大数据Hadoop生态学习笔记(一)
Hadoop 概述
什么是 Hadoop
可扩展的、简洁的数据存储、处理及分析系统(生态)
架构图
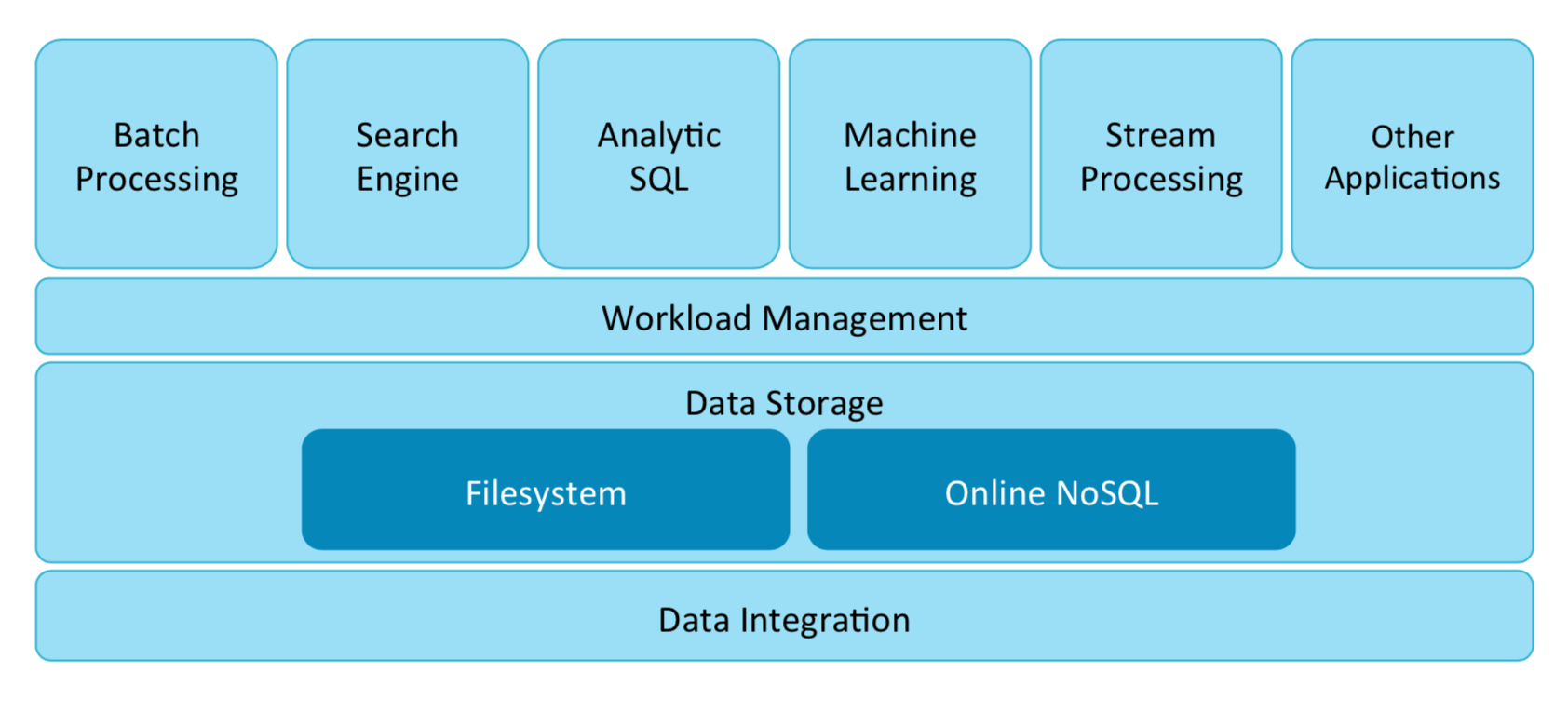
Hadoop 解决的问题
- 传统数据存储在一个中央数据库,当程序需要数据时,数据会被复制给程序
- 传统方式对于少量数据可以很好的处理,但不利于海量数据
Hadoop 的方案
- 数据分布式存储(HDFS)
- 程序计算直接在数据存储的地方运行
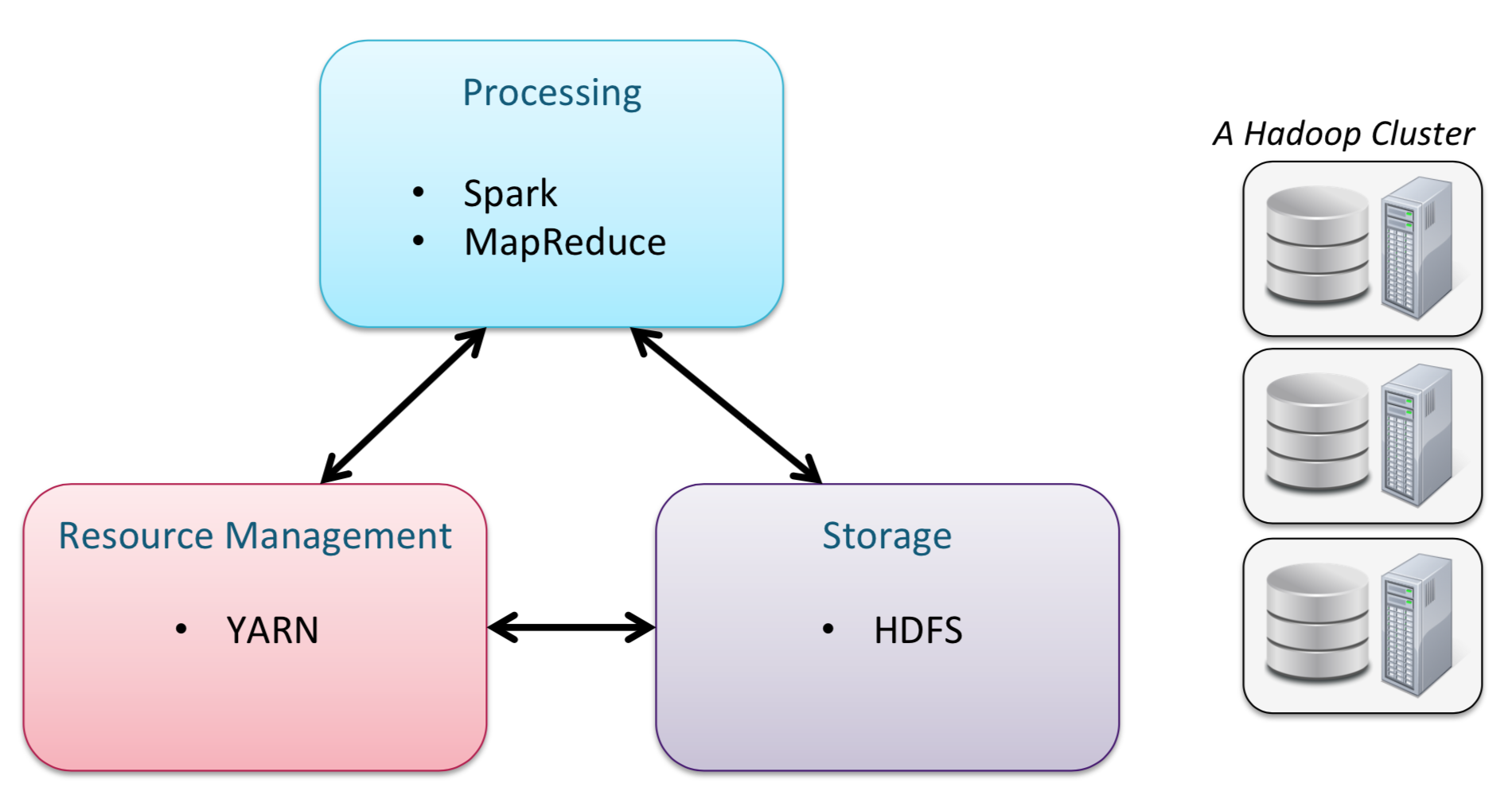
- 示意图
大数据的处理流程
数据采集
数据源
- 传统数据库,如 MySQL
- 日志和运行时产生的文件
- 直接导入文件
数据采集工具
- Flume
- Kafka
- Sqoop
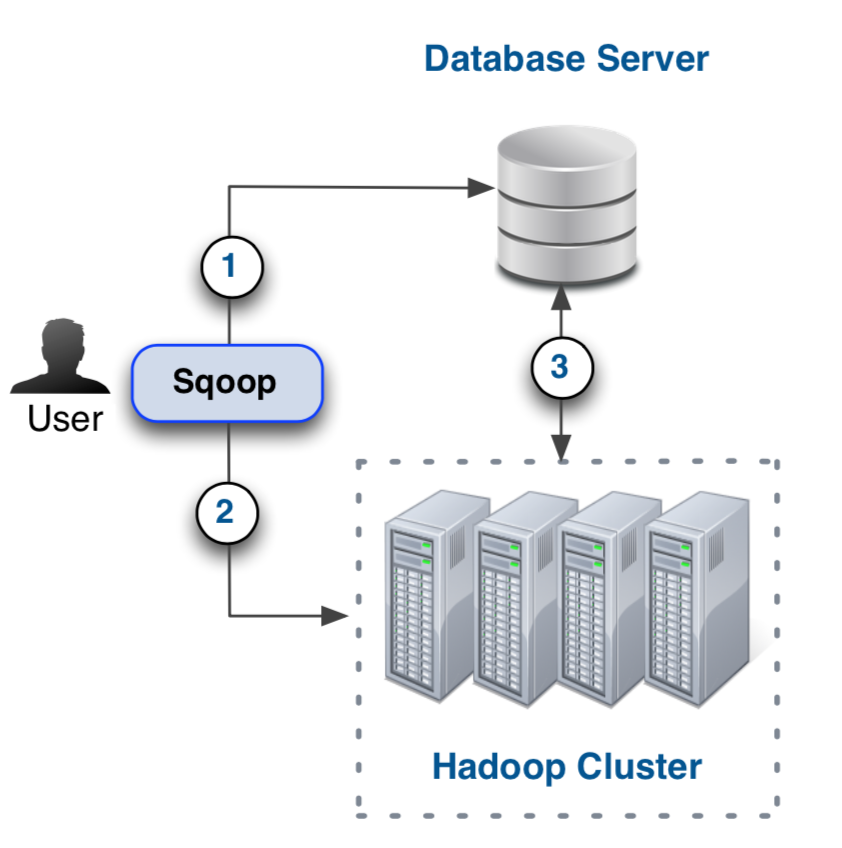
Sqoop
- 作用:将数据从传统数据库导入至 HDFS,或将数据从 HDFS 导出至传统数据库
- 工作流程示意图:
- Sqoop Shell 命令操作
数据存储
一、 HDFS
概念
- Hadoop Cluster:多台计算机组成一个 Cluster,每台计算机称为 Node,Node 分为 MasterNode 和 WorkerNode
特点
- 分布式
- 块存储
- NameNode 存储元数据
- “write once”
- 对大量的文件读取进行优化
使用
- Shell
- Spark
- 其他程序
目录结构(Recommend)
- /user:用户文件
- /ert: Work in progress in Extract/Transform/Load stage
- /tmp: 临时文件
- /data: 通用数据
- /app: 无数据文件,如配置文件
Yarn
- HDFS 的一个资源调度工具
- Daemons
- Resource Manager
- Node Manager
- Application
- Container
- Application Master
二、 HBase
数据处理
一、 Spark
Spark Shell
- Python Shell
- Scala Shell
RDD (Resilient Distributed Dataset)
创建 RDD
从文件创建
1
val mydata = sc.textFile("purplecow.txt")
从内存中的数据创建
从其他 RDD 创建
RDD Operations
- Actions
- count()
- take(n)
- collect()
- saveAsTextFile(file)
- …
- Transformations
- map(function)
- filter(function)
- Lazy Execution
- Chain Transformations
- Actions
函数式编程
- 伪代码:
1 | RDD { |
- Scala
1 | mydata.map(line => line.toUpperCase()).take(2) |
二、 MapReduce
三、 Pig
数据分析
- Impala
- Hive
Feature
- 提供 SQL 的方式查询 HDFS/HBase 的数据
- 示意图
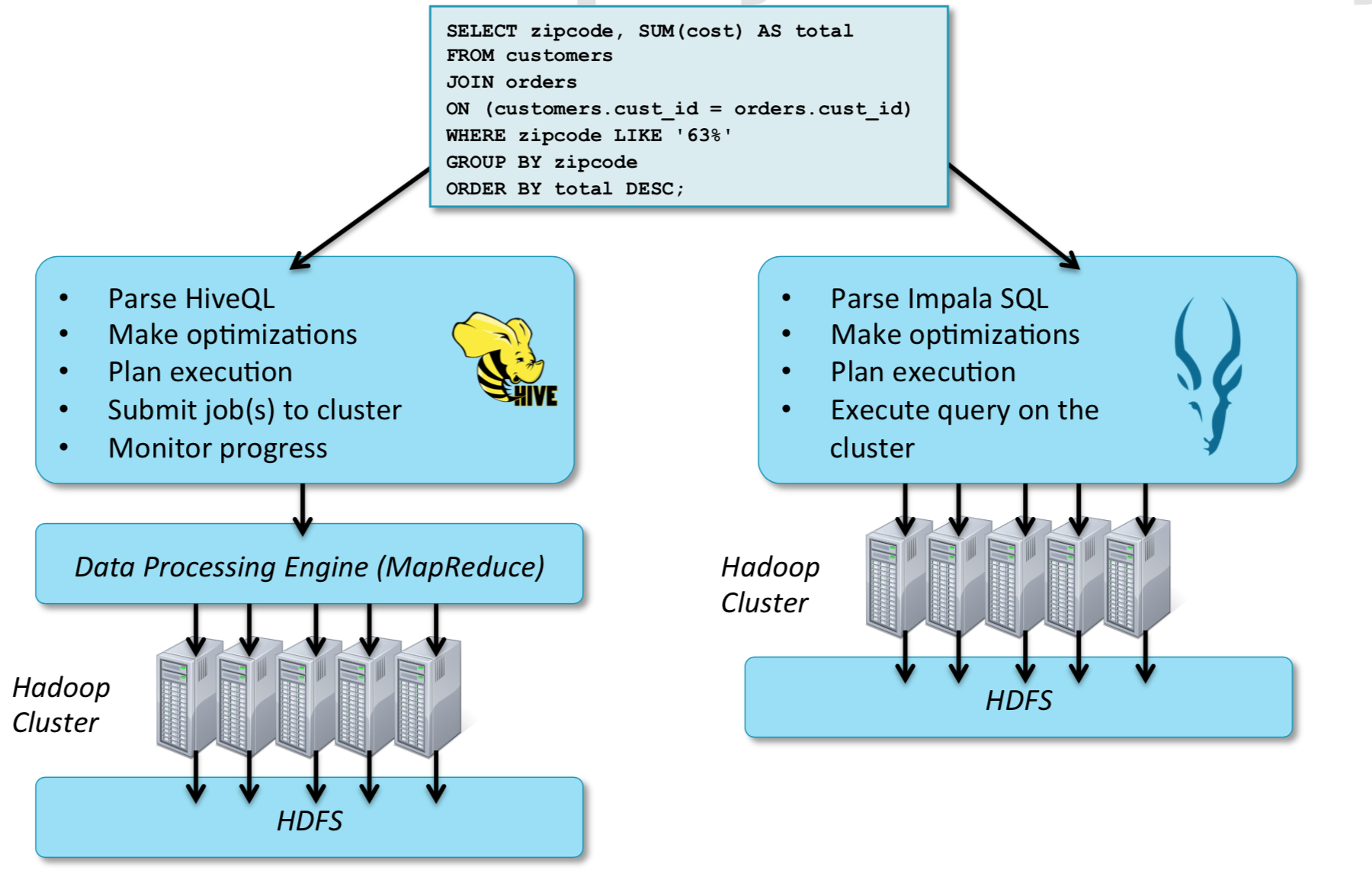
- Impala 直接操作 HDFS
- Hive 通过 MapReduce 操作 HDFS
Why Hive or Impala
- Brings large-scale data analysis to a broader audience
- More produc.ve than wri.ng MapReduce or Spark directly
- Offers interoperability with other systems
使用
- Impala Shell
- BeeLine (Hive Shell)
注意
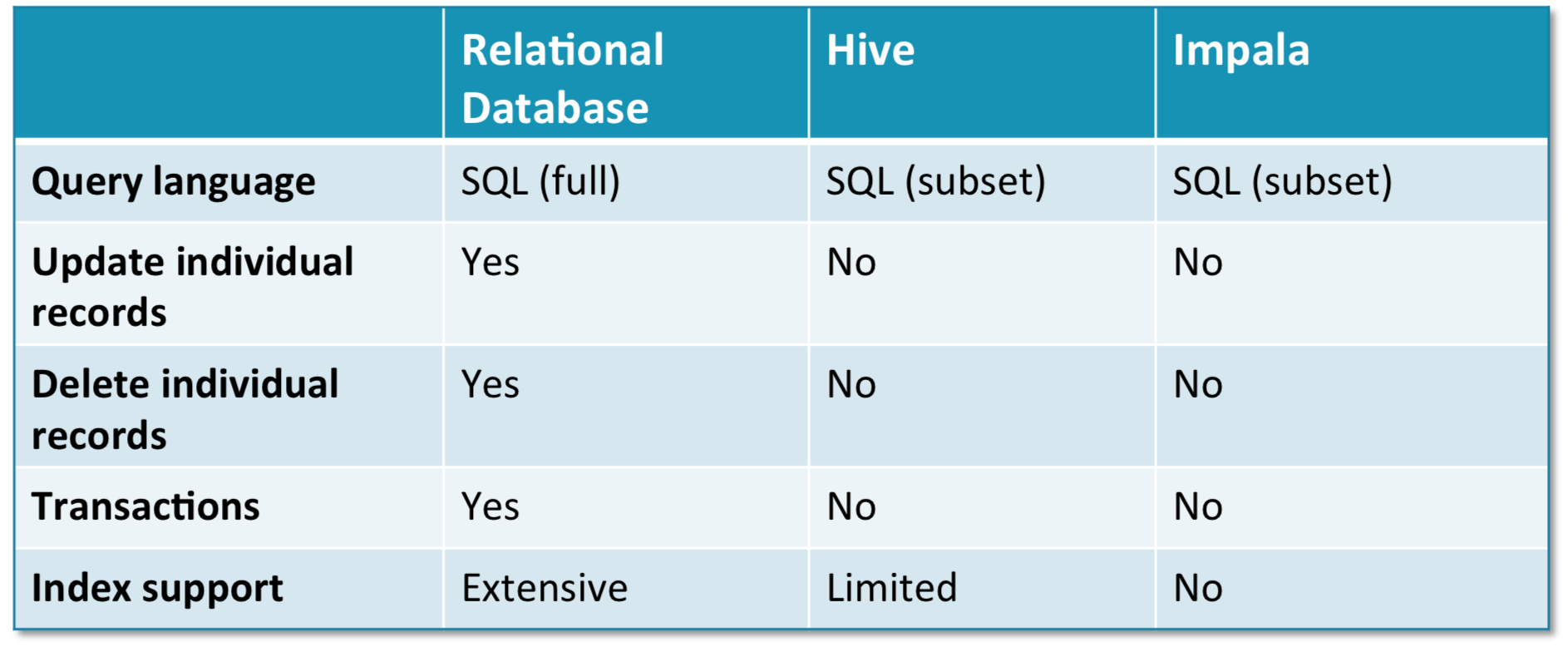
- Impala 和 Hive 提供 SQL 方式与存储层交互,但此时的 Cluster 不能等同于传统的关系数据库
- Impala/Hive 同传统关系型数据库的对比图
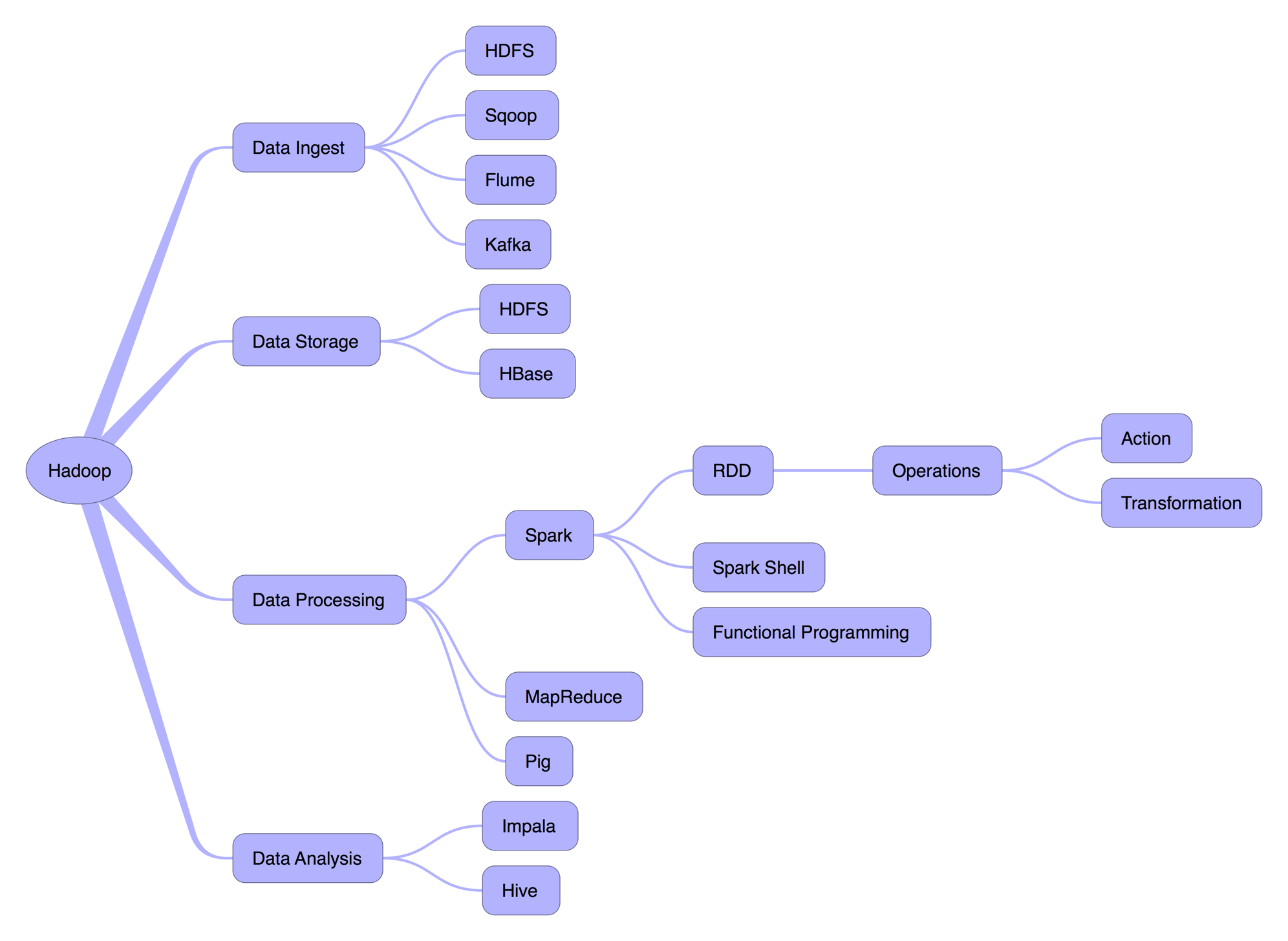
知识体系图